SQL Server Replication Best Practices
Overview
Secret Server geo replication is SQL Server replication using a set of technologies for copying and distributing data and database objects from one database to another and then synchronizing between databases to maintain consistency across geographically distributed data centers.
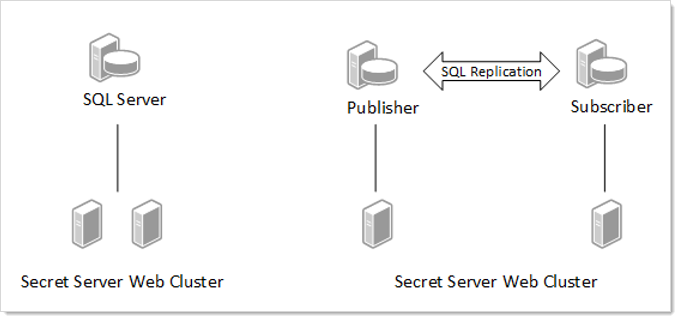
SQL Server Replication
Figure: SQL Server Replication
Benefits of Replication
Enabling SQL Server replication allows a database and application to be hosted closer together and this allows for the mitigation of network latency and outages.
- Decrease application server to database network latency
- Resolve issues with unreliable network connectivity
- Allows for distribution of workload in a scale out fashion
- Works across large distances
In a typical web-clustered version of Secret Server, all application servers access a centralized database. In the event of a network outage, any users on affected application servers are not be able to use Secret Server until network access was restored. In addition, poorly performing networks can introduce latency that may decrease the responsiveness of Secret Server. This technology provides additional options when designing the network topology behind Secret Server that can help alleviate these issues.
High Availability
SQL Server replication is not an option for high availability, but it can be coupled with other technologies like SQL Server AlwaysOn Availability Groups to provide high availability. Any architecture should be reviewed and designed with your database group.
Architecture
The SQL Server Replication technologies do all the work of ensuring data consistency between each database, and Secret Server is designed to work well with this technology. When SQL Server replication is enabled on a specified database several system tables, views, stored procedures, and SQL Server jobs are added to the database schema. These tables store information about the data replication, and the procedures contain most of the code needed to perform the synchronization between databases.
Data Synchronization
This is the process through which SQL Server replication integrates changes from each database node. These changes include data changes as well as schema changes. Each subscribing database node has a synchronization interval that defines when it will synchronize any changes between the main publication node and itself. Secret Server has been tested using pull-based subscriptions where a scheduled job on each SQL Server subscriber runs at a specified interval to trigger the synchronization.
Data Conflicts
Enabling SQL Server replication introduces the possibility of data conflicts occurring in the Secret Server environment. This can happen when two people in different regions attempt to update the same set of data. Due to the disconnected nature of the technology, the system is unaware of this conflict until a data synchronization occurs. During synchronization, SQL Server attempts to resolve any conflicts based on a defined set of parameters. Secret Server provides a setup script to help define optimal parameters for each article (table, view, and stored procedure) in the Secret Server database.
SQL Server Replication Monitor and Conflict Viewer
For more information:
Tracking level
SQL Server replication tracks changes to each node by either row or column:
For more information on row- and column-level tracking, see Row-Level Security
Conflict Resolvers
SQL Server replication uses resolvers to determine the outcome of data conflicts between two database nodes. For example, the same row or column was updated on different nodes. These can be as simple as the publisher database always wins, last change by date wins, and many others.
Switch nodes over to subscriber databases. Any nodes that are configured to run background, engine, or session recording roles must remain on the publisher database.
For more information see:
Secret Server and SQL Replication
There are many architectures for how SQL Replication can be setup. Determining the correct configuration requires proper planning with a good understanding of how SQL Replication works and the intended goals of using this technology. Here are a few examples.
Figure: Web Cluster with SQL Server Replication
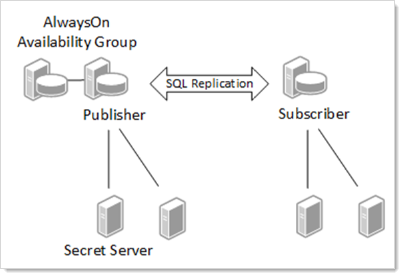
Some key points about designing the right architecture:
- Multiple web application servers can connect to the same database server.
- Secret Server allows you to configure various roles (background, engine, session recording) that perform various services, such as heartbeat and password changing. These roles can only function on a node that has a connection to the publisher database and will not run on other nodes even if configured to do so. If no suitable node is available that has roles enabled and is connected to the publisher database, then certain activities such as secret heartbeat and remote password changing will be offline until such a node becomes available.
- Secret Server Engines are an effective means to distribute workload to different networks or sites. Each engine must call back to a Web application node that connects to a publisher database.
-
The diagram shows the publisher in an AlwaysOn availability group, but this is just an example. Depending on the needs of the organization, AlwaysOn could run on both the publisher and the subscribers or on neither. Many other high availability options could be leveraged alongside SQL
Replication.
Using a Subscriber When the Publisher Is Offline
Figure: Using a Subscriber When the Publisher Is Offline
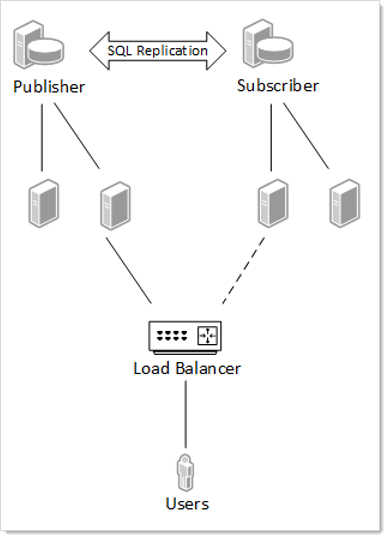
In the event of a network outage, a load balancer could be configured to fail over to the subscriber nodes. The data on the subscriber would be as up to date as the last synchronization, and when network connectivity is restored all data activity will be synchronized again. Obviously, if the issues of network latency or disconnects occur too frequently, this may not be a workable solution.
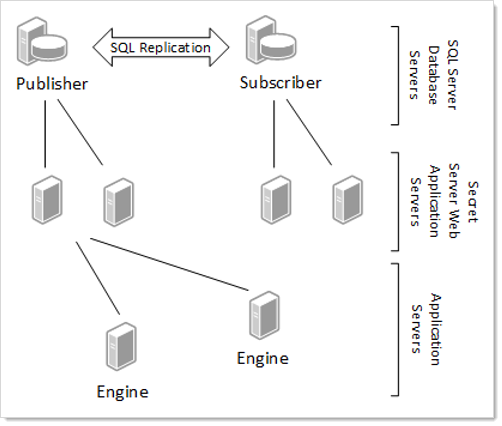
Secret Server Distributed Engine
You can add Secret Server distributed engines to different network segments, but you must still be able to call back to a Secret Server Web application server that is connected to a publisher database node. This helps to ensure that heartbeats and password changes occur with the most up to date dataset.
Figure: SQL Replication and Distributed Engines
Secret Server Replication Settings
Keep in mind that this is a disconnected technology, so there are required decisions when setting it up:
- How often should synchronization occur?
- Should any resolvers override the provided defaults?
- Are there any operational considerations based on the type of secret data?
Publications
- Events: These are things that need to occur on a timely schedule, such as updating secrets. The events publication should be set to synchronize every minute. This means that if a secret were created in one region, it would not appear in another region for one minute. By default, this publication is called SSPubEvents.
- Logs: Information from each audit log is available on its server. We do not recommend setting log synchronization to less than hour. If this happens too frequently, the database could create deadlocks by constantly updating large sets of data. Once the logs merge, the events will appear in the order in which they occur and show on the server on which they took place. By default, this publication is called SSPubLogs.
Using the default Secret Server implementation, most conflicts are resolved by taking the change made on the publication server as the winner (using the "publisher wins" resolver). It is assumed that the publication server is most likely the main server in an environment and therefore, most likely, the decider in a case of a conflict. Thus, we recommend doing functions, such as configuration changes or secret template definition changes, on the publication node. This is only an issue if two people update the same data on two different servers before a synchronization occurs.
There are some exceptions to the "publisher always wins" rule:
| Data Element | Resolver or Tracking Level | |
|---|---|---|
| Secret Fields | Last Update Wins | If two people change a password on a secret to a new password, then the last person to make the change will win. |
| Secret Access Request Approval | Last Update Wins | If two people are in a group that is requested to approve access, then the last person to approve or disapprove access would set that approval. |
| File Attachment | Last Update Wins | |
| tbConfiguration | Column Level | Configuration changes are resolved by table column, not the default row-level where the entire row is resolved. This allows different configuration options to be set on different servers and not conflict with each other, but changing the same option would create a conflict. |
Always remember that the conflict is only resolved when synchronization occurs. If there is a synchronization window of 24 hours, there could be very different data on different servers for that entire 24-hour period. The risk of data conflicts increases with larger synchronization windows. The default recommended synchronization is every minute for most items and every hour for system logs.
For a complete listing of recommended settings navigate to the SQL Replication Administration page in an installed version of Secret Server at ADMIN > Nodes > SQL Server Replication > Show Articles.
Conflict Auditing
When conflicts occur during synchronization, Secret Server writes an event to the system log on the server that it has detected these conflicts. Depending on the type of conflict, more-specific information maybe written to the audit log for a specific data entity, such as a secret or folder. Notification of the conflict is written to the system, secret audit, folder audit, and other logs. To view complete details of the conflict, the SQL Conflict Viewer tool needs to be used to review the conflict by right clicking on the publication and choosing to View Conflicts.
As an example, if the same field changed on two different servers, resulting in a conflict, then the Secret Server audit log will indicate the field was changed twice and then denote that there was a data conflict.
Operational Latency
Give consideration to how your Secret Server data is setup and managed. This is most easily described by an example where a manager uses a Secret Server node in Europe and their employee works on a node in Australia. Due to network latency, the organization has changed the default event log synchronization interval from every minute to every five minutes. The employee requests access to a secret in Australia, but due to the synchronization window, the manager is not alerted until five minutes later because the manager is using the server in Europe. You can mitigate this issue by having operational groups work on data for their region or decreasing the synchronization window.
Options to manage data latency if data conflicts occur regularly:
When setting up the SQL Replication Publication certain articles need settings other than the default settings. The recommended settings can be found within Secret Server by accessing the SQL Server Replication page located at Admin > Nodes > SQL Server Replication > Show Articles. This page can also be used to generate a setup script for both the Publication and Subscribers that uses these default settings. A Distributor will need to be created before running these scripts. For more information, see Configuring Distribution.
Compensate for Errors
When conflicts occur, an article that has the compensate_for_errors attribute set to true will automatically try to resolve the conflict. When false, a SQL Server administrator can use the SQL Server Conflict Viewer to review and resolve conflicts.
Identity Range
SQL Server replication manages table identities by assigning ranges to the publisher and subscribers. Certain tables (logging or auditing) require larger assigned identity ranges. New ranges are only assigned when a data synchronization occurs. For more information, see Replicate Identity Columns.
Variations
How SQL Server replication is setup can vary greatly and there may be reasons to not use the standard setup. Consult with your database group for approaches that may work well in your environment. The architecture diagrams contained within this document are just high-level examples.
Installation
There are a multitude of configuration options for SQL Server replication. At a high level, these are the steps to setup Secret Server in a SQL Server replicated environment:
-
Review what settings are appropriate for the distributor setup with your on-premise database group or with a database consultant.
-
Download the SQL publication script.
-
In Secret Server select ADMIN > Nodes > SQL Server Replication >Get SQL Publication Script.
-
Review this script and update the variables according to your environment.
-
-
Run this script on the Secret Server Database. A DBA with administrative privileges is needed to run this. Please consult with your on-premise database group or review your configuration with a database consultant.
-
Create snapshots for each publication:
-
Open SQL Server Management Studio
-
Right click on each publication under Replication > Local Publications
-
Select View Snapshot Agent Status.
-
Click Start
-
-
Download the SQL subscriber script:
-
In Secret Server select ADMIN > Nodes > SQL Server Replication >Get SQL Subscriber Script.
-
Review this script and update the variables to match your environment
-
-
Create a new database on the database server you intend to be your subscriber. Ensure the script uses this database and machine name. Set up permissions for the user or network account that Secret Server uses to connect to this database.
-
Run the subscriber script on the publication database first and then on the subscriber database. If your variables are set properly, it will execute the appropriate part of the script.
-
Expand the SQL Server Jobs on the subscriber, and you should see two jobs named for each publication.
-
Right click these jobs to start them. After they complete, your subscriber database should have replicated the schema objects from the publication.
-
Switch Secret Server nodes over to subscriber databases. The primary node must remain on the Publisher database, as must any node that an engine calls back to, but all other nodes can be reconfigured to use subscriber databases. Which nodes to switch depends on your specific needs as described in the previous sections. To switch an existing node to a subscriber database, log into that node and go the DbConnectionReset.aspx page by entering that page name in the URL field of your browser (
http[s]://<your_secret_server_name>/DbConnectionReset.aspx). Step through the wizard, entering the name of the new server and database when prompted. After completing this step, recycle the node's application pool.
Troubleshooting the Installation
Replication Setup Scripts Fail
Make sure that the SQL Server replication feature is enabled before running the script. Check the error messages in the script output. Make sure you set all of the variables in the top of the script correctly (such as publisher server, database names, and subscriber server).
SQL Replication Job Fails
To see the error message, it is easiest to right click on the job and choose to view history. This error message can indicate the actual problem.
Removing SQL Server Replication
Certain operations such as upgrading Secret Server, adding or removing DoubleLocks from secrets, and enabling or disabling HSM cannot be performed while SQL Server replication is enabled. In order to perform these operations you must remove SQL Server replication. When you are done with the action that required you to remove replication you can install and configure it again by repeating the previous instructions.
You only need to remove replication from the Publisher and all Subscribers. The Replication Distributer does not need to be removed. These are the steps to remove SQL Server replication from your publisher and subscriber databases.
On Each Subscriber
- Stop the websites of all nodes using the subscriber database.
-
In SQL Server Management Studio, go to , right-click Local Subscriptions and choose
-
In the dialog, click to select "Subscriptions in the following data sources" and select the Secret Server subscription databases.
-
Click Generate Script > Open in new query window.
-
The script contains sections to be run on both the subscriber and the publisher. Run the sections on the subscriber by uncommenting them and commenting those for the publisher.
-
Copy the script to a query window on the publisher server.
-
The script contains sections to be run on both the subscriber and the publisher. Run the sections on the publisher by uncommenting them and commenting those for the subscriber.
-
Perform any maintenance actions needed on the subscriber database and nodes.
On the Publisher
-
Stop the websites of all nodes using the publisher database.
-
On the publisher, go to Replication, right-click Local Publications and choose Generate Scripts...
-
In the Generate SQL Script dialog check Publications in thefollowing data sources and select the Secret Server database.
-
Click to deselect the Distributor Properties check box.
-
Select To drop or disable the components.
-
Click Close to close the dialog once the script is created.
-
Run the script.
-
Perform any maintenance actions needed on the subscriber database and nodes.
-
After all maintenance tasks are done, restore replication as described in Disaster Recovery and Resilient Secrets.
Managing SQL Server Replication
Once replication is setup and working certain considerations should be given to managing it along with conflicts that can occur. The recommended settings for the publication have been tested to limit conflicts, but they can still occur. Here are some scenarios you might encounter:
| Scenario | Solution |
|---|---|
| Conflict automatically resolved | SQL Server was able to determine how to resolve the conflict. Secret Server will log and audit this conflict. To see the specific details for the conflict, use the SQL Server Conflict Viewer in SQL Server Management Studio. |
| Conflict unable to be automatically resolved | A user with SQL Server access needs to open the conflict in SQL Server Management Studio. Access these by right-clicking on the publication and choosing to view conflicts. |
| Some data stops replicating | A table could become blocked if there are conflicts. Other data may continue to synchronize. If data in one region or database node is different than another after a synchronization, there could be conflicts that need to be reviewed and resolved. |
| SQL Replication Synchronization Times | The status of each publication and subscribing server along with the last time of synchronization can be located in Secret Server by selecting . |
Web Server Nodes
The Web Server Nodes page now includes a column that lists the database server name and database name. This column also indicates whether the database is the publisher or a subscriber. To see the page:
-
Open Secret Server.
-
Click the Admin menu item and select All.
-
Click the Server Nodes button. The Server Nodes page appears (not shown).
-
If you click the SQL Server Replication button, you can see more information about your SQL Server replication. The page pulls from the replication data and shows the:
- Publication name
- SQL server
- Database
- Subscription type (push or pull)
- Status of the last sync
- Last time that subscription was synced
- Date of the last sync
As mentioned earlier, the Get SQL Publication Script and Get SQL Subscriber Script buttons will download replication script templates that you can use to set up replication for Secret Server. You can fill in the variables at the top of each script to match your environment and run them as-is or modify them further if you need to customize the default scripts.
The Show Articles button lists each article in Secret Server that should be included in replication along with the recommended settings for SQL Server replication. These are recommended settings and do not show the current state of replication on the publisher.
Upgrade Scenario
New versions of Secret Server may issue schema changes including indexes, column changes, and views. In some cases, SQL merge replication will not automatically replicate these schema changes. For this reason, we recommend removing any publications and subscriptions targeting the Secret Server database, redirecting users to the web server at the primary site before performing any upgrade, and recreating the publication and subscriptions from new versions of the replication scripts.
In the following scenario, there are Secret Server web servers installed at a site in Australia, the U.S., and the U.K. The U.K. is the publisher node and Australia and U.S. nodes are the subscribers.
-
Redirect all users to the U.K. Secret Server URL.
-
Stop IIS at the Australia and U.S. sites.
-
Manually force a synchronization between the Australia subscriber and the U.K:
-
Open SQL Server Management Studio and connect to the Australia subscriber database server.
-
Go to Replication > Local Subscriptions.
-
Right-click on one of the Secret Server subscriptions (if you used the scripts provided by Secret Server, they are called SSPubLogs and ) and select View Synchronization Status.
-
Click the Start button to force a synchronization.
-
-
Repeat sub-steps 3 and 4 for all Secret Server subscriptions.
-
Repeat sub-step 3 for the U.S. subscriber database.
-
Resolve any replication conflicts:
-
Open SQL Server Management Studio and connect to the UK publisher database server.
-
Go to Replication > Local Publications.
-
Right-click on one of the Secret Server publications (if you used the scripts provided by Secret Server they are called SSPubLogs and SSPubEvents) and select View Conflicts.
-
Examine and resolve any unresolved conflicts.
-
-
Generate the script to remove replication on the subscriber databases as specified above.
-
Run it to remove replication.
-
Generate the script to remove replication on the publisher database as specified above.
-
Run it to remove replication.
-
Restart IIS on the Secret Server web server in the U.K.
-
Run the Secret Server web upgrade wizard.
-
Copy the website application directory to the web servers in Australia and the U.S.
-
Use the scripts generated from the Secret Server UI to recreate replication on the publisher.
-
Push a snapshot to the Australia and U.S. subscriber databases.
-
Recreate replication at the subscribers.
-
Restart the jobs on the subscriber databases as described above.
-
Start IIS on the Australia and U.S. web servers.
-
Change redirection rules for Australia and U.S. users so they access the local WithWeb server as normal.
Other Information about SQL Server Replication
- Upgrading Secret Server with SQL Replication
- SQL Server Replication (MS Books Online)
- Snapshot Replication